
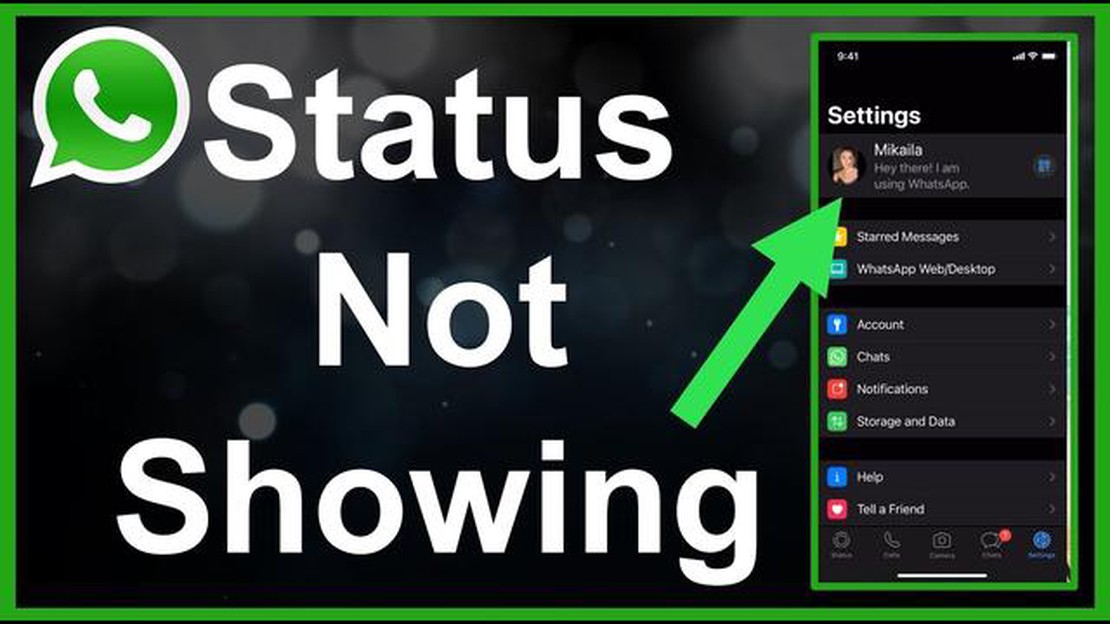

Varför visas inte vänners status i WhatsApp och hur löser man problemet?
Varför kan jag inte se mina vänners status på whatsapp (fixa detta) WhatsApp är en av de mest populära budbärarna i världen som låter dig dela …
Läs artikel
Machine learning och deep learning är två termer som ofta används inom artificiell intelligens. De representerar olika tillvägagångssätt för att bearbeta data och skapa algoritmer för automatisk inlärning och förutsägelse. Även om båda metoderna används för att lösa problem med maskininlärning finns det ett antal grundläggande skillnader mellan dem.
Maskininlärning är ett tillvägagångssätt som bygger på användning av algoritmer och modeller som gör det möjligt för en dator att lära sig av data och förutsäga resultat. I maskininlärning bearbetas data med hjälp av statistiska och matematiska tekniker och algoritmer optimeras för bästa prestanda. Exempel på maskininlärning är algoritmer för klassificering, regression och klustring.
Till skillnad från maskininlärning använder djupinlärning artificiella neurala nätverk för att utforska stora mängder data. Ett djupt neuralt nätverk består av flera lager, där varje lager utför specifika beräkningar. Deep learning kan bearbeta komplexa data, t.ex. bilder eller ljud, på en högre abstraktionsnivå och göra mer exakta förutsägelser.
Tillämpningar av deep learning omfattar områden som datorseende, bearbetning av naturligt språk, rekommendationssystem och röstgränssnitt. Företag som Google, Facebook och Microsoft använder aktivt deep learning för att förbättra sina produkter och tjänster. De bygger neurala nätverk som kan känna igen objekt i bilder, översätta text från ett språk till ett annat och generera tal från textdata.
Deep Learning är en underavdelning av maskininlärning som modellerar och analyserar högnivåabstraktioner av data med hjälp av artificiella neurala nätverk med flera lager. Detta tillvägagångssätt gör det möjligt för en dator att bearbeta och förstå data på samma sätt som den mänskliga hjärnan gör.
Den grundläggande principen för hur djupinlärning fungerar är att använda artificiella neurala nätverk som består av flera lager. Varje lager består av neuroner som överför och bearbetar information.
Till skillnad från klassisk maskininlärning, där fokus ligger på att utforma och välja funktioner för att bearbeta data, gör djupinlärning det möjligt att modellera funktioner direkt från själva data, utan behov av manuell bearbetning.
De viktigaste principerna för djupinlärning är följande:
Deep learning har breda tillämpningar inom olika områden som datorseende, taligenkänning, naturlig språkbehandling, rekommendationssystem och många andra. Med sin förmåga att extrahera komplexa mönster från data blir djupinlärning ett kraftfullt verktyg för att lösa komplexa problem och skapa innovativ teknik.
Djupinlärning (deep learning) är en underavdelning av maskininlärning som använder neurala nätverk med många lager för att automatiskt extrahera och representera komplexa datastrukturer. Till skillnad från traditionell maskininlärning, där människor identifierar och utformar funktioner, låter djupinlärning modellen lära sig på egen hand från stora mängder data.
Den största skillnaden mellan deep learning och maskininlärning är att deep learning-modellerna kan extrahera hierarkiska funktioner från data. Varje lager i det neurala nätverket tränas för att känna igen mer abstrakta och komplexa egenskaper hos data. Sådana modeller har förmågan att automatiskt extrahera funktioner på olika abstraktionsnivåer, vilket gör att de kan visa hög effektivitet och noggrannhet när det gäller att lösa komplexa problem.
Deep learning används inom flera olika områden, bland annat datorseende, bearbetning av naturligt språk, talteknik och ljudbehandling. Neurala nätverk med djupinlärning används för klassificeringsuppgifter, objektdetektering och igenkänning, innehållsgenerering med mera.
Träning av djupa neurala nätverk kräver en stor mängd partitionerade data. Utvecklingen av GPU:er och tillgången till stor datorkraft har dock gjort djupinlärning mer tillgänglig. Dessutom finns det många förtränade modeller som du kan använda i dina projekt, vilket gör det lättare att skapa och träna dina egna modeller.
Deep learning är en underavdelning av maskininlärning som bygger på algoritmer för artificiella neurala nätverk. Den grundläggande principen för djupinlärning är att bygga och träna djupa neurala nätverk som består av många lager.
Ett neuralt nätverk består av en uppsättning artificiella neuroner som kombineras i lager. Varje lager utför vissa operationer på indata och skickar resultaten vidare nedåt i nätverket. Ett lager innehåller vikter som automatiskt optimeras under träningsprocessen.
Deep learning skiljer sig från klassisk maskininlärning genom att det gör det möjligt att skapa modeller som automatiskt kan extrahera hierarkiska egenskaper från indata. Varje lager i det neurala nätverket bearbetar data på olika abstraktionsnivåer, vilket gör det möjligt för deep learning-modellen att producera högre noggrannhet och mer komplexa funktioner.
Läs också: Aktivera Fortnite 2-faktor autentisering (2FA) - Ny 2023 steg-för-steg-guide
I träningsprocessen går ett djupt neuralt nätverk igenom flera steg. Först matas indata till det första lagret, som tillämpar aktiveringsalgoritmer på indata och skickar resultaten till nästa lager. Efterföljande lager bearbetar data och skickar dem vidare till utgångslagret, som är resultatet av modellen.
En av de största utmaningarna med djupinlärning är det stora antalet parametrar och modellernas komplexitet. Att träna djupa neurala nätverk kräver en betydande mängd data, beräkningsresurser och tid. Men tack vare den tekniska utvecklingen och tillkomsten av specialiserade hårdvaruacceleratorer blir djupinlärning alltmer tillgängligt och används inom en mängd olika områden, bland annat datorseende, bearbetning av naturligt språk, robotteknik med mera.
Maskininlärning är en underavdelning av artificiell intelligens som studerar de metoder med vilka datorprogram lär sig automatiskt utan att vara uttryckligen programmerade. Det bygger på idén att datorsystem kan bearbeta och analysera stora mängder data för att identifiera mönster och göra förutsägelser eller fatta beslut baserade på dessa data.
Maskininlärning använder algoritmer och matematiska modeller för att träna en dator baserat på data. Det finns olika metoder för maskininlärning, bland annat övervakad inlärning, oövervakad inlärning och förstärkningsinlärning.
Läs också: Så här aktiverar du haptisk feedback på iPhone-tangentbordet (iOS 16)
Vid supervised learning tränas modellen på märkta data, där varje dataexempel motsvarar ett korrekt svar. Supervised learning används ofta för att lösa klassificerings- eller regressionsproblem.
Vid oövervakad inlärning tränas modellen på omärkta data där det inte finns några tydliga korrekta svar. Oövervakad inlärning används för att hitta dolda strukturer eller kluster i data, upptäcka avvikelser eller minska dimensionaliteten hos data.
Vid förstärkningsinlärning tränas modellen baserat på dess interaktion med omgivningen. Den får feedback eller belöningar för sina handlingar, vilket gör att den kan förbättra sin lösningsförmåga.
Maskininlärning har ett brett spektrum av tillämpningar, inklusive upptäckt av bedrägerier, rekommendationssystem, medicinsk diagnostik, datorseende, autonoma fordon och mycket mer.
Viktiga tekniker för maskininlärning inkluderar:
Maskininlärning är en viktig teknik i dagens värld och fortsätter att utvecklas och hitta nya tillämpningar. Den gör det möjligt för datorer att extrahera värdefull information från data och fatta intelligenta beslut baserat på denna information.
Maskininlärning är en del av artificiell intelligens som studerar och utvecklar metoder som gör det möjligt för datorer att lära sig av data och göra förutsägelser eller fatta beslut utan att vara uttryckligen programmerade.
De grundläggande principerna för maskininlärning inkluderar:
I allmänhet är maskininlärning en iterativ process där en modell tränas på data och sedan används för att göra förutsägelser eller fatta beslut baserat på nya data. Maskininlärning har ett brett spektrum av tillämpningar inom olika områden, inklusive datorseende, naturlig språkbehandling, rekommendationssystem och mycket mer.
Den största skillnaden mellan deep learning och maskininlärning är att deep learning är en underavdelning av maskininlärning som använder neurala nätverk med flera lager för att analysera och bearbeta data. Deep learning är alltså en mer sofistikerad och djupgående metod för inlärning som ger mer exakta resultat av högre kvalitet.
Olika algoritmer används inom maskininlärning, t.ex. linjär regression, supportvektormetod (SVM), random forest och andra. Inom djupinlärning är de viktigaste algoritmerna artificiella neurala nätverk som konvolutionella neurala nätverk (CNN) och återkommande neurala nätverk (RNN) och deras kombinationer och modifieringar.
Djupinlärning och maskininlärning har ett brett spektrum av tillämpningar. De används inom bild- och videobearbetning och analys, taligenkänning, maskinöversättning, röstassistenter, självkörande bilar, medicinsk diagnostik, finansiell analys, rekommendationssystem och många andra områden.
De främsta fördelarna med deep learning jämfört med maskininlärning är förmågan att automatiskt extrahera egenskaper från data, bättre generaliserbarhet för modeller, förmågan att hantera stora datamängder och förmågan att uppnå högre noggrannhet i resultaten. Dessutom kan deep learning bearbeta data av olika slag, t.ex. bilder, ljud och text, på en hög nivå.
Deep learning är en delmängd av maskininlärning och är en teknik som bygger på artificiella neurala nätverk med ett stort antal dolda lager. Medan maskininlärning omfattar ett brett spektrum av metoder och algoritmer, fokuserar djupinlärning på bearbetning och analys av stora datamängder med hjälp av djupa neurala nätverk.
Varför kan jag inte se mina vänners status på whatsapp (fixa detta) WhatsApp är en av de mest populära budbärarna i världen som låter dig dela …
Läs artikel
Så hittar du borttappade Galaxy Buds | hitta dina försvunna Samsung-öronsnäckor Har du någonsin letat febrilt efter dina borttappade Galaxy Buds eller …
Läs artikel
De 12 bästa Android operativsystemen för PC 2023 (32,64 bit). Android OS, som utvecklats av Google, är ett av de mest populära operativsystemen på …
Läs artikel
Samsung Chromebook Pro vs Ny Microsoft Surface Pro 2-i-1 Laptop Spec Jämförelse Samsung Chromebook Pro och nya Microsoft Surface Pro är två mycket …
Läs artikel
Så här fixar du en Samsung Galaxy S7 som har frusit fast med svart skärm som inte svarar (felsökningsguide) Samsung Galaxy S7 är en populär …
Läs artikel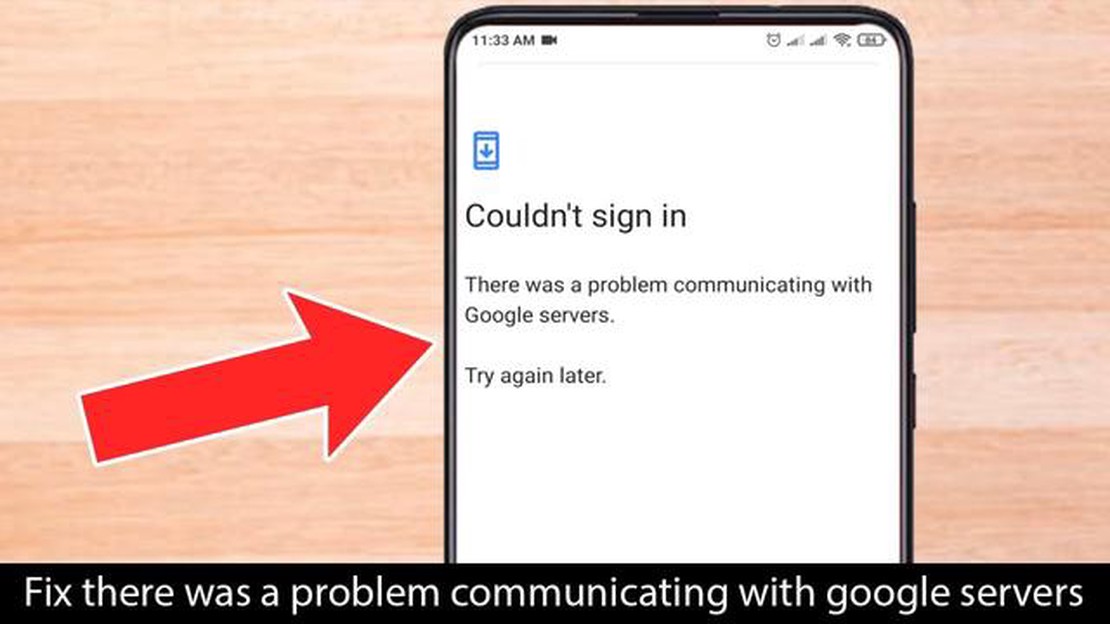
Problem med att kommunicera med Google Servers Fel Om du använder en Android-enhet har du förmodligen stött på det frustrerande felmeddelandet …
Läs artikel

