
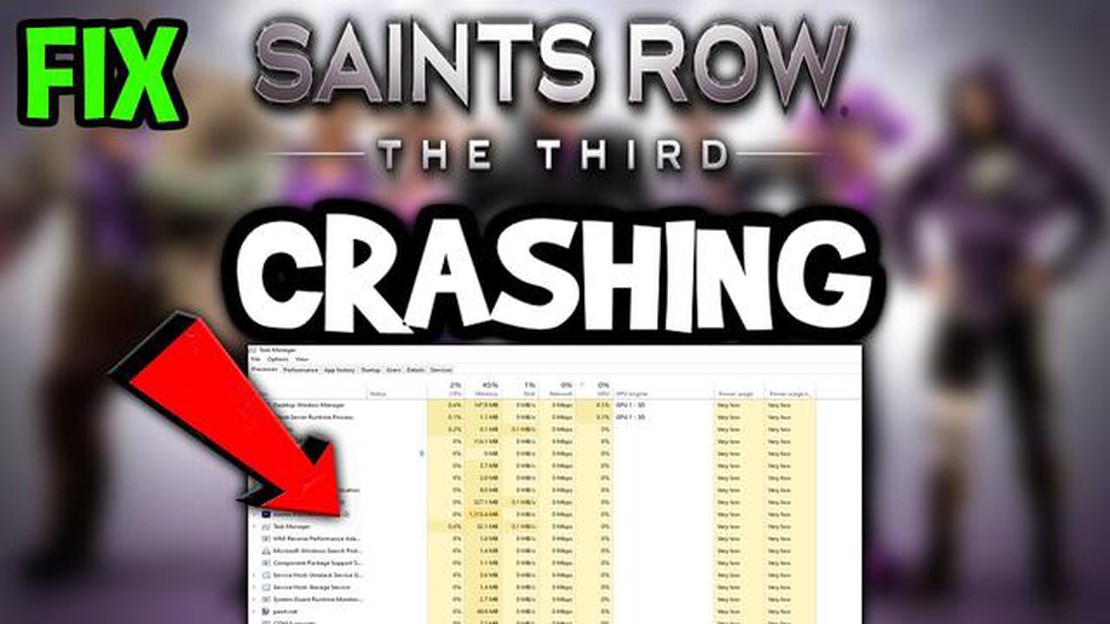

Hvorfor Saints Row krasjer på PC: årsaker og løsninger på problemet
Saints row krasjer på pc Saints Row er en populær serie PC-spill som er viden kjent for sine åpne verdener spekket med action og humor. Noen …
Les artikkelen
Maskinlæring og dybdelæring er to begreper som ofte brukes innen kunstig intelligens. De representerer ulike tilnærminger til behandling av data og utvikling av algoritmer for automatisk læring og prediksjon. Selv om begge metodene brukes til å løse maskinlæringsproblemer, er det en rekke grunnleggende forskjeller mellom dem.
Maskinlæring er en tilnærming basert på bruk av algoritmer og modeller som gjør det mulig for en datamaskin å lære av data og forutsi utfall. I maskinlæring behandles data ved hjelp av statistiske og matematiske teknikker, og algoritmene optimaliseres for best mulig ytelse. Eksempler på maskinlæring er klassifiserings-, regresjons- og klyngealgoritmer.
I motsetning til maskinlæring bruker dyp læring kunstige nevrale nettverk til å utforske store datamengder. Et dypt nevralt nettverk består av flere lag, der hvert lag utfører spesifikke beregninger. Dyp læring er i stand til å behandle komplekse data, for eksempel bilder eller lyd, på et høyere abstraksjonsnivå og gi mer nøyaktige prediksjoner.
Dyp læring brukes blant annet innen datasyn, naturlig språkbehandling, anbefalingssystemer og stemmegrensesnitt. Selskaper som Google, Facebook og Microsoft bruker dyp læring aktivt for å forbedre sine produkter og tjenester. De bygger nevrale nettverk som kan gjenkjenne objekter i bilder, oversette tekst fra ett språk til et annet og generere tale fra tekstdata.
**Dyp læring er en underavdeling av maskinlæring som modellerer og analyserer data på høyt abstraksjonsnivå ved hjelp av kunstige nevrale nettverk med flere lag. Denne tilnærmingen gjør det mulig for en datamaskin å behandle og forstå data på samme måte som den menneskelige hjerne.
Det grunnleggende prinsippet for hvordan dyp læring fungerer, er å bruke kunstige nevrale nettverk som består av flere lag. Hvert lag består av nevroner som overfører og behandler informasjon.
I motsetning til klassisk maskinlæring, der fokuset ligger på å designe og velge ut funksjoner for å behandle dataene, gjør dyp læring det mulig å modellere funksjoner direkte fra selve dataene, uten behov for manuell behandling.
De viktigste prinsippene for dyp læring er
Dyp læring har mange bruksområder, blant annet innen datasyn, talegjenkjenning, naturlig språkbehandling og anbefalingssystemer. Med sin evne til å trekke ut komplekse mønstre fra data blir dybdelæring et kraftig verktøy for å løse komplekse problemer og skape innovative teknologier.
Dyp læring (deep learning) er en underavdeling av maskinlæring som bruker nevrale nettverk med mange lag for automatisk å trekke ut og representere komplekse datastrukturer. I motsetning til tradisjonell maskinlæring, der mennesker identifiserer og utformer funksjoner, lar dyp læring modellen lære på egen hånd fra store datamengder.
Hovedforskjellen mellom dybdelæring og maskinlæring er dybdelæringsmodellenes evne til å trekke ut hierarkiske funksjoner fra data. Hvert lag i det nevrale nettverket trenes opp til å gjenkjenne mer abstrakte og komplekse egenskaper ved dataene. Slike modeller har evnen til automatisk å trekke ut egenskaper på ulike abstraksjonsnivåer, noe som gjør dem svært effektive og nøyaktige til å løse komplekse problemer.
Dyp læring brukes på en rekke områder, blant annet innen datasyn, naturlig språkbehandling, taleteknologi og lydbehandling. Dyplærende nevrale nettverk brukes blant annet til klassifiseringsoppgaver, gjenkjenning og gjenkjenning av objekter og generering av innhold.
Trening av dype nevrale nettverk krever store mengder data. Utviklingen av GPU-er og tilgjengeligheten av stor datakraft har imidlertid gjort dyp læring mer tilgjengelig. I tillegg finnes det mange ferdig trente modeller som du kan bruke i prosjektene dine, noe som gjør det enklere å lage og trene opp egne modeller.
Dyp læring er en underavdeling av maskinlæring som er basert på algoritmer for kunstige nevrale nettverk. Det grunnleggende prinsippet for dyp læring er å bygge og trene opp dype nevrale nettverk som består av mange lag.
Et nevralt nettverk består av et sett med kunstige nevroner som er satt sammen i lag. Hvert lag utfører bestemte operasjoner på inngangsdataene og sender resultatene videre nedover i nettverket. Et lag inneholder vekter som optimaliseres automatisk under treningsprosessen.
Dyp læring skiller seg fra klassisk maskinlæring ved at det gjør det mulig å lage modeller som automatisk kan trekke ut hierarkiske funksjoner fra inngangsdataene. Hvert lag i det nevrale nettverket behandler dataene på ulike abstraksjonsnivåer, noe som gjør det mulig for deep learning-modellen å produsere mer nøyaktige og komplekse funksjoner.
I opplæringsprosessen går et dypt nevralt nettverk gjennom flere trinn. Først mates inngangsdata inn i det første laget, som bruker aktiveringsalgoritmer på inngangsdataene og sender resultatene videre til neste lag. De påfølgende lagene behandler dataene og sender dem videre til utgangslaget, som er resultatet av modellen.
Les også: De 15 beste appene for å gjøre musikk langsommere på Android og iOS
En av hovedutfordringene med dyp læring er det store antallet parametere og modellenes kompleksitet. Opplæring av dype nevrale nettverk krever en betydelig mengde data, beregningsressurser og tid. På grunn av teknologiske fremskritt og fremveksten av spesialiserte maskinvareakseleratorer blir dyp læring imidlertid stadig mer tilgjengelig og brukes på en rekke områder, blant annet innen datasyn, naturlig språkbehandling og robotteknologi.
Maskinlæring er en underavdeling av kunstig intelligens som studerer metodene som gjør at dataprogrammer lærer automatisk uten å være eksplisitt programmert. Det er basert på ideen om at datasystemer kan behandle og analysere store datamengder for å identifisere mønstre og gjøre forutsigelser eller ta beslutninger basert på disse dataene.
Les også: Den legendariske Google Pixel 2 og Pixel 2XL: den siste oppdateringen
Maskinlæring bruker algoritmer og matematiske modeller for å trene opp en datamaskin basert på data. Det finnes ulike metoder for maskinlæring, blant annet veiledet læring, ikke-veiledet læring og forsterkningslæring.
Ved veiledet læring trenes modellen på merkede data, der hvert dataeksempel tilsvarer et riktig svar. Overvåket læring brukes ofte til å løse klassifiserings- eller regresjonsproblemer.
Ved ikke-overvåket læring trenes modellen på umerkede data der det ikke finnes noen eksplisitte riktige svar. Ikke-veiledet læring brukes til å finne skjulte strukturer eller klynger i dataene, oppdage avvik eller redusere dataenes dimensjonalitet.
Ved forsterkningslæring trenes modellen opp basert på interaksjon med omgivelsene. Den får tilbakemelding eller belønning for sine handlinger, noe som gjør at den kan forbedre sine løsningsevner.
Maskinlæring har et bredt spekter av bruksområder, inkludert oppdagelse av svindel, anbefalingssystemer, medisinsk diagnostikk, datasyn, autonome kjøretøy og mye mer.
Viktige maskinlæringsteknikker inkluderer:
** ** Beslutningstre: Det konstrueres et tre der hver node representerer en egenskap, og hver gren representerer en mulig verdi for denne egenskapen. Treet brukes til klassifisering eller prediksjon.
Maskinlæring er en viktig teknologi i dagens verden og fortsetter å utvikle seg og finne nye bruksområder. Den gjør det mulig for datamaskiner å trekke ut verdifull informasjon fra data og ta intelligente beslutninger basert på denne informasjonen.
Maskinlæring er en underavdeling av kunstig intelligens som studerer og utvikler metoder som gjør det mulig for datamaskiner å lære av data og gjøre forutsigelser eller ta beslutninger uten å være eksplisitt programmert.
De grunnleggende prinsippene for maskinlæring er blant annet
Generelt er maskinlæring en iterativ prosess der en modell trenes opp på data og deretter brukes til å gjøre prediksjoner eller ta beslutninger basert på nye data. Maskinlæring har et bredt spekter av bruksområder, blant annet datasyn, naturlig språkbehandling og anbefalingssystemer.
Hovedforskjellen mellom dybdelæring og maskinlæring er at dybdelæring er en underavdeling av maskinlæring som bruker nevrale nettverk med flere lag for å analysere og behandle data. Dyp læring er dermed en mer sofistikert og dyptgående tilnærming til læring som gir mer nøyaktige resultater av høyere kvalitet.
Ulike algoritmer brukes i maskinlæring, for eksempel lineær regresjon, støttevektormetoden (SVM), random forest og andre. I dyp læring er hovedalgoritmene kunstige nevrale nettverk som convolutional neural networks (CNN) og recurrent neural networks (RNN) og kombinasjoner og modifikasjoner av disse.
Dyp læring og maskinlæring har et bredt spekter av bruksområder. De brukes innen bilde- og videobehandling og -analyse, talegjenkjenning, maskinoversettelse, stemmeassistenter, selvkjørende biler, medisinsk diagnostikk, finansiell analyse, anbefalingssystemer og mange andre områder.
De viktigste fordelene med dyp læring sammenlignet med maskinlæring er evnen til automatisk å trekke ut egenskaper fra data, bedre generaliserbarhet av modeller, evnen til å håndtere store datamengder og muligheten til å oppnå mer nøyaktige resultater. I tillegg kan dyp læring behandle data av ulik art, for eksempel bilder, lyd og tekst, på et høyt nivå.
Dyp læring er en undergruppe av maskinlæring og er en teknikk basert på kunstige nevrale nettverk med et stort antall skjulte lag. Mens maskinlæring dekker et bredt spekter av metoder og algoritmer, fokuserer dyp læring på behandling og analyse av store datamengder ved hjelp av dype nevrale nettverk.
Saints row krasjer på pc Saints Row er en populær serie PC-spill som er viden kjent for sine åpne verdener spekket med action og humor. Noen …
Les artikkelen
Slik spiller du Call of Duty: Modern Warfare med delt skjerm. Call of Duty: Modern Warfare er et av de mest populære spillene i førstepersons …
Les artikkelen
Hvordan sletter jeg spotify-kontoen permanent? Spotify er en av de mest populære musikkplattformene i verden og gir brukerne tilgang til en enorm …
Les artikkelen
Slik løser du problemet med tilfeldig frysing av Nintendo Switch | Oppdatert (Oppdatert 2023) Hvis du er en stolt eier av en Nintendo Switch, vet du …
Les artikkelen
8 problemer du kan støte på under eller etter oppdatering av Samsung Galaxy S6 Edge og hvordan du løser dem Samsung Galaxy S6 Edge er en populær …
Les artikkelen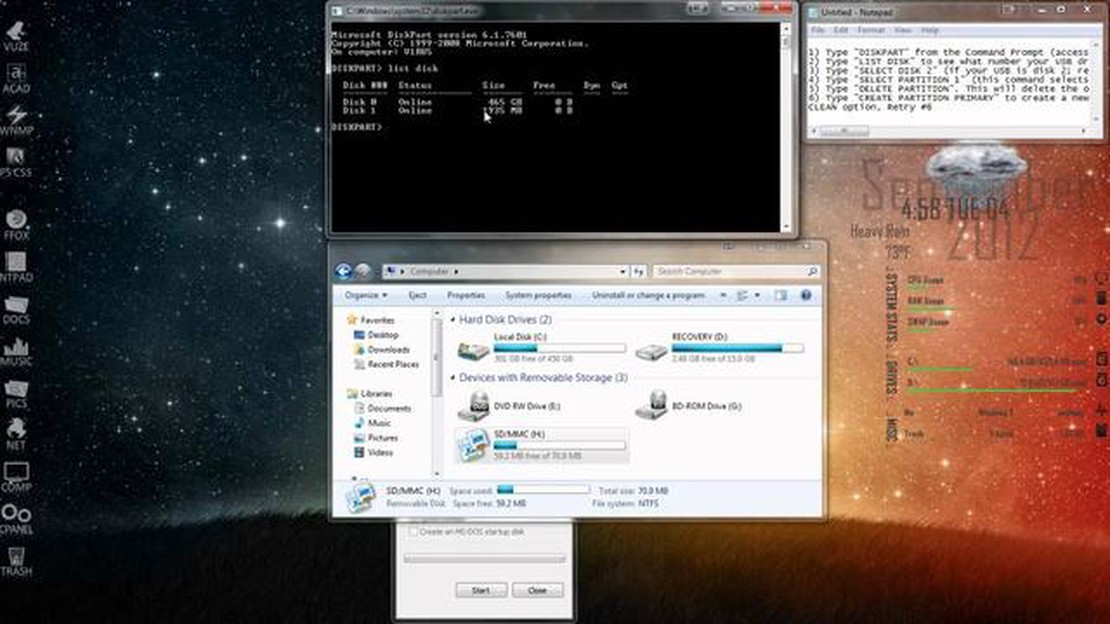
Hvordan gjenopprette tapt plass på en USB-pinne USB-minnepinner er blitt en integrert del av hverdagen vår. Vi bruker dem til å lagre og overføre …
Les artikkelen


