

Le 12 migliori alternative a Omegle: siti simili per video chat occasionali
12 siti come omegle: alternative per video chat occasionali. Omegle è uno dei siti più popolari per le chat video casuali con gli sconosciuti. …
Leggi l'articolo
Machine learning e deep learning sono due termini spesso utilizzati nel campo dell’intelligenza artificiale. Rappresentano approcci diversi all’elaborazione dei dati e alla creazione di algoritmi per l’apprendimento automatico e la previsione. Sebbene entrambi i metodi siano utilizzati per risolvere i problemi di apprendimento automatico, esistono alcune differenze fondamentali.
L’apprendimento automatico è un approccio basato sull’uso di algoritmi e modelli che consentono a un computer di imparare dai dati e di prevedere i risultati. Nell’apprendimento automatico, i dati vengono elaborati utilizzando tecniche statistiche e matematiche e gli algoritmi vengono ottimizzati per ottenere le migliori prestazioni. Esempi di apprendimento automatico sono gli algoritmi di classificazione, regressione e clustering.
A differenza dell’apprendimento automatico, l’apprendimento profondo utilizza reti neurali artificiali per esplorare grandi quantità di dati. Una rete neurale profonda è composta da molti strati, ognuno dei quali esegue calcoli specifici. L’apprendimento profondo è in grado di elaborare dati complessi, come immagini o suoni, a un livello di astrazione superiore e di fare previsioni più accurate.
Le applicazioni dell’apprendimento profondo includono settori come la visione artificiale, l’elaborazione del linguaggio naturale, i sistemi di raccomandazione e le interfacce vocali. Aziende come Google, Facebook e Microsoft utilizzano attivamente il deep learning per migliorare i loro prodotti e servizi. Stanno costruendo reti neurali in grado di riconoscere oggetti nelle immagini, di tradurre testi da una lingua all’altra e di generare discorsi da dati testuali.
Il Deep Learning è una sottosezione dell’apprendimento automatico che modella e analizza astrazioni di alto livello dei dati utilizzando reti neurali artificiali a più livelli. Questo approccio consente a un computer di elaborare e comprendere i dati nello stesso modo in cui lo fa il cervello umano.
Il principio di base del funzionamento dell’apprendimento profondo è l’utilizzo di reti neurali artificiali composte da più livelli. Ogni strato è costituito da neuroni che trasmettono ed elaborano informazioni.
A differenza dell’apprendimento automatico classico, in cui l’attenzione si concentra sulla progettazione e sulla selezione delle caratteristiche per elaborare i dati, l’apprendimento profondo consente di modellare le caratteristiche direttamente dai dati stessi, senza la necessità di un’elaborazione manuale.
I principali principi operativi del deep learning sono:
L’apprendimento profondo trova ampie applicazioni in vari campi, come la visione artificiale, il riconoscimento vocale, l’elaborazione del linguaggio naturale, i sistemi di raccomandazione e molti altri. Grazie alla sua capacità di estrarre modelli complessi dai dati, il deep learning diventa uno strumento potente per risolvere problemi complessi e creare tecnologie innovative.
L’apprendimento profondo (deep learning) è una sottosezione dell’apprendimento automatico che utilizza reti neurali con molti strati per estrarre e rappresentare automaticamente strutture di dati complesse. A differenza dell’apprendimento automatico tradizionale, in cui l’uomo identifica e progetta le caratteristiche, l’apprendimento profondo consente al modello di imparare da solo da grandi quantità di dati.
La differenza principale tra deep learning e machine learning è la capacità dei modelli di deep learning di estrarre caratteristiche gerarchiche dai dati. Ogni strato della rete neurale viene addestrato a riconoscere caratteristiche più astratte e complesse dei dati. Tali modelli hanno la capacità di estrarre automaticamente caratteristiche a diversi livelli di astrazione, il che consente loro di mostrare un’elevata efficienza e accuratezza nella risoluzione di problemi complessi.
L’apprendimento profondo trova applicazione in diversi campi, tra cui la visione artificiale, l’elaborazione del linguaggio naturale, la tecnologia vocale e l’elaborazione audio. Le reti neurali ad apprendimento profondo sono utilizzate per compiti di classificazione, rilevamento e riconoscimento di oggetti, generazione di contenuti e altro ancora.
L’addestramento delle reti neurali profonde richiede una grande quantità di dati partizionati. Tuttavia, lo sviluppo delle GPU e la disponibilità di una grande potenza di calcolo hanno reso il deep learning più accessibile. Inoltre, esistono molti modelli pre-addestrati che possono essere utilizzati nei progetti, rendendo più semplice la creazione e l’addestramento dei propri modelli.
Il deep learning è una sottosezione dell’apprendimento automatico che si basa su algoritmi di reti neurali artificiali. Il principio di base del deep learning consiste nel costruire e addestrare reti neurali profonde composte da molti strati.
Una rete neurale consiste in un insieme di neuroni artificiali raggruppati in strati. Ogni strato esegue determinate operazioni sui dati in ingresso e trasmette i risultati a valle della rete. Uno strato contiene pesi che vengono ottimizzati automaticamente durante il processo di addestramento.
L’apprendimento profondo si differenzia dall’apprendimento automatico classico per la possibilità di creare modelli in grado di estrarre automaticamente caratteristiche gerarchiche dai dati in ingresso. Ogni strato della rete neurale elabora i dati a diversi livelli di astrazione, consentendo al modello di apprendimento profondo di produrre una maggiore precisione e caratteristiche più complesse.
Leggi anche: 8 modi per aumentare il numero di abbonati su TikTok
Nel processo di addestramento, una rete neurale profonda attraversa diverse fasi. In primo luogo, i dati di ingresso vengono inviati al primo strato, che applica algoritmi di attivazione ai dati di ingresso e passa i risultati allo strato successivo. Gli strati successivi elaborano i dati e li trasmettono allo strato di uscita, che rappresenta il risultato del modello.
Una delle sfide principali dell’apprendimento profondo è l’elevato numero di parametri e la complessità dei modelli. L’addestramento delle reti neurali profonde richiede una quantità significativa di dati, risorse computazionali e tempo. Tuttavia, grazie ai progressi tecnologici e all’avvento di acceleratori hardware specializzati, il deep learning sta diventando sempre più accessibile e viene utilizzato in una moltitudine di campi, tra cui la computer vision, l’elaborazione del linguaggio naturale, la robotica e altri ancora.
L’apprendimento automatico è una sottosezione dell’intelligenza artificiale che studia i metodi con cui i programmi informatici imparano automaticamente senza essere programmati esplicitamente. Si basa sull’idea che i sistemi informatici possano elaborare e analizzare grandi quantità di dati per identificare modelli e fare previsioni o prendere decisioni in base a tali dati.
L’apprendimento automatico utilizza algoritmi e modelli matematici per addestrare un computer in base ai dati. Esistono diversi metodi di apprendimento automatico, tra cui l’apprendimento supervisionato, l’apprendimento non supervisionato e l’apprendimento per rinforzo.
Leggi anche: Come ridurre i costi di trasferimento in Football Manager 2020? Idee e strategie
Nell’apprendimento supervisionato, il modello viene addestrato su dati etichettati, dove ogni esempio di dati corrisponde a una risposta corretta. L’apprendimento supervisionato viene spesso utilizzato per risolvere problemi di classificazione o regressione.
Nell’apprendimento non supervisionato, il modello viene addestrato su dati non etichettati, dove non ci sono risposte corrette esplicite. L’apprendimento non supervisionato viene utilizzato per trovare strutture o cluster nascosti nei dati, individuare anomalie o ridurre la dimensionalità dei dati.
Nell’apprendimento per rinforzo, il modello viene addestrato in base alla sua interazione con l’ambiente. Riceve un feedback o una ricompensa per le sue azioni, che gli permette di migliorare le sue capacità di risoluzione.
L’apprendimento automatico ha un’ampia gamma di applicazioni, tra cui il rilevamento delle frodi, i sistemi di raccomandazione, la diagnostica medica, la computer vision, i veicoli autonomi e altro ancora.
Le principali tecniche di apprendimento automatico includono:
L’apprendimento automatico è una tecnologia chiave nel mondo di oggi e continua ad evolversi e a trovare nuove applicazioni. Consente ai computer di estrarre informazioni preziose dai dati e di prendere decisioni intelligenti sulla base di tali informazioni.
L’apprendimento automatico è una sottosezione dell’intelligenza artificiale che studia e sviluppa metodi che consentono ai computer di imparare dai dati e di fare previsioni o prendere decisioni senza essere esplicitamente programmati.
I principi di base dell’apprendimento automatico includono:
Utilizzo dei dati: l’apprendimento automatico richiede una grande quantità di dati su cui il modello verrà addestrato. Questi dati possono essere sotto forma di valori numerici, testo, immagini e altri formati.
In generale, l’apprendimento automatico è un processo iterativo in cui un modello viene addestrato sui dati e poi utilizzato per fare previsioni o prendere decisioni sulla base di nuovi dati. Ha un’ampia gamma di applicazioni in vari campi, tra cui la visione artificiale, l’elaborazione del linguaggio naturale, i sistemi di raccomandazione e altro ancora.
La differenza principale tra deep learning e machine learning è che il deep learning è una sottosezione del machine learning che utilizza reti neurali con più livelli per analizzare ed elaborare i dati. Il deep learning è quindi un approccio più sofisticato e approfondito all’apprendimento che consente di ottenere risultati più accurati e di qualità superiore.
Nell’apprendimento automatico vengono utilizzati diversi algoritmi, come la regressione lineare, il metodo del vettore di supporto (SVM), la foresta casuale e altri. Nell’apprendimento profondo, gli algoritmi principali sono le reti neurali artificiali come le reti neurali convoluzionali (CNN) e le reti neurali ricorrenti (RNN) e le loro combinazioni e modifiche.
L’apprendimento profondo e l’apprendimento automatico hanno un’ampia gamma di applicazioni. Sono utilizzati nell’elaborazione e nell’analisi di immagini e video, nel riconoscimento vocale, nella traduzione automatica, negli assistenti vocali, nelle automobili autonome, nella diagnostica medica, nell’analisi finanziaria, nei sistemi di raccomandazione e in molti altri settori.
I principali vantaggi dell’apprendimento profondo rispetto all’apprendimento automatico sono la capacità di estrarre automaticamente le caratteristiche dai dati, una migliore generalizzabilità dei modelli, la capacità di gestire grandi quantità di dati e la capacità di ottenere una maggiore precisione dei risultati. Inoltre, il deep learning è in grado di elaborare dati di natura diversa, come immagini, audio e testo, a un livello elevato.
Il deep learning è un sottoinsieme del machine learning ed è una tecnica basata su reti neurali artificiali con un gran numero di strati nascosti. Mentre l’apprendimento automatico copre un’ampia gamma di metodi e algoritmi, il deep learning si concentra sull’elaborazione e l’analisi di grandi quantità di dati utilizzando reti neurali profonde.
12 siti come omegle: alternative per video chat occasionali. Omegle è uno dei siti più popolari per le chat video casuali con gli sconosciuti. …
Leggi l'articolo
Red dead redemption 3: rockstar sta lavorando a un nuovo gioco rdr? Red Dead Redemption 3: il seguito del pluripremiato e amato gioco di Rockstar …
Leggi l'articolo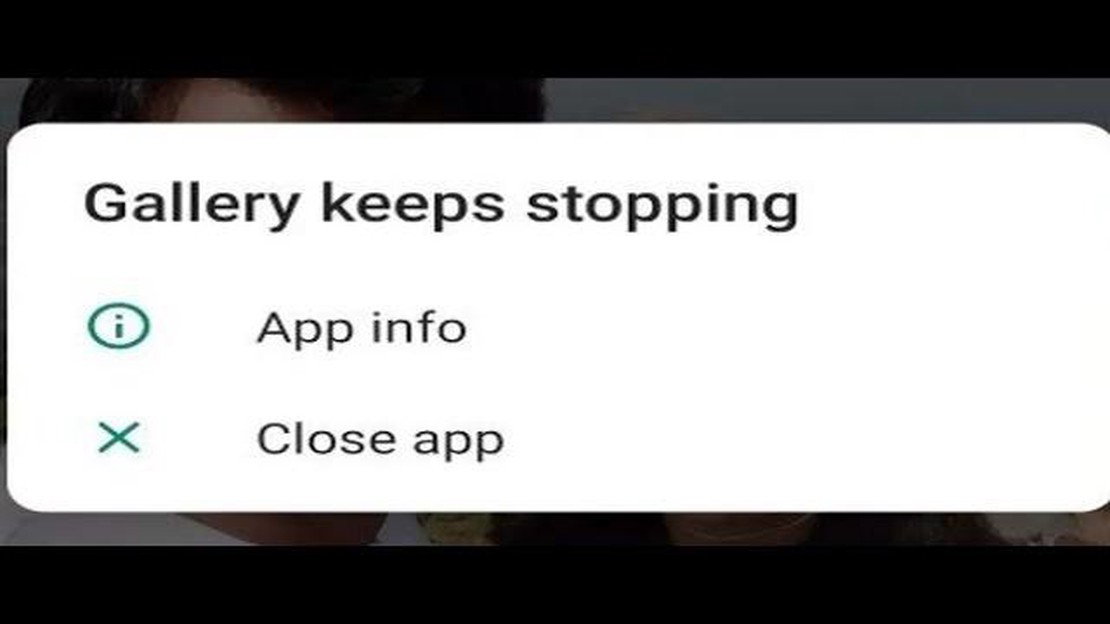
L’errore “Purtroppo la Galleria si è fermata” continua a comparire su Samsung Galaxy A3 (Guida alla risoluzione dei problemi) Se possedete un Samsung …
Leggi l'articolo
13 Migliori localizzatori GPS nascosti per auto Se volete tenere d’occhio il vostro adolescente alla guida, proteggere il vostro veicolo dal furto o …
Leggi l'articolo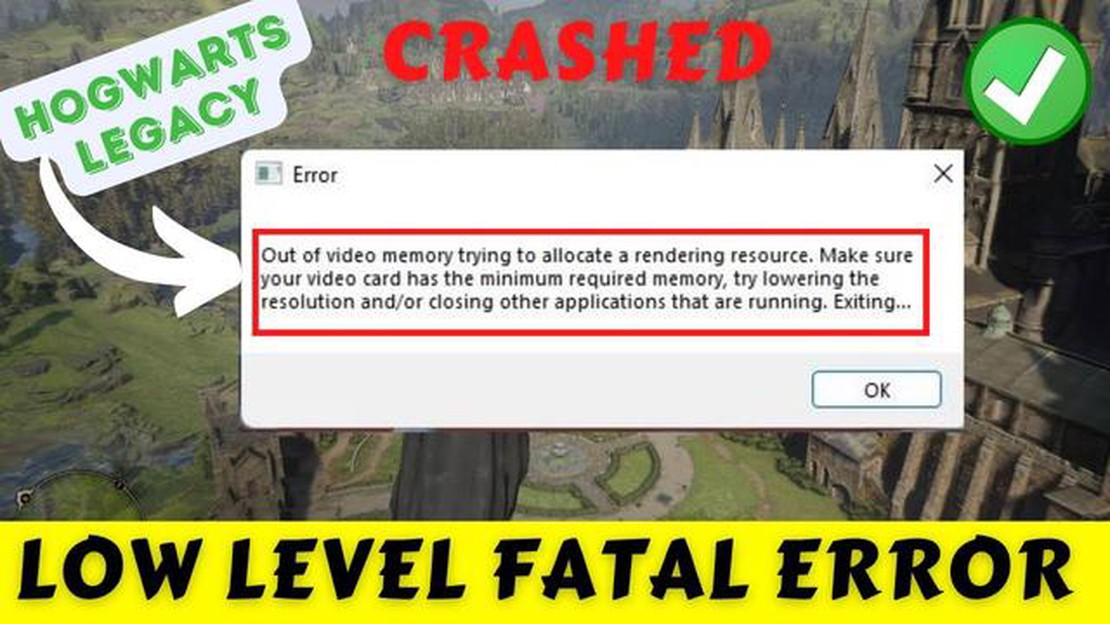
Come risolvere l’errore di memoria video esaurita di Hogwarts Legacy Hogwarts Legacy è un videogioco molto atteso ambientato nel mondo magico di Harry …
Leggi l'articolo
Come giocare ai giochi PS2 su PC Grazie ai progressi della tecnologia, è ora possibile giocare ai giochi per PlayStation 2 (PS2) sul PC. Questo apre …
Leggi l'articolo


